Wenn das Kernel-Gedächnis streikt…, Teil 1
3. August 2010Der berühmt/berüchtigte „Blue Screen of Death“ ist wohl bei allen Administratoren nur zu gut bekannt und hat bei den meisten wohl auch schon für ungewollte Überstunden gesorgt. Aber nicht nur das Ereignis an sich ist das Problem – viel schwieriger ist es oft, im Nachhinein festzustellen, wer oder was beispielsweise einen entsprechend schwerwiegenden Fehler im Hauptspeicher verursacht hat. In einem zweiteiligen Artikel zeigt ein Mitarbeiter des Microsoft Windows Escalation Teams, wie man auf die Suche gehen und fündig werden kann.
Wer als IT-Administrator tätig ist, kennt ohne Zweifel die immer wieder auftretende Blue-Screen-Abstürze der Windows-Systeme, die manchmal auch quasi im „Vorbeigehen“ auftreten. Die Amerikaner haben dafür den schönen Ausdruck „drive-by blue screen crashes“. Natürlich treten derartige Vorfälle immer zu einem total unpassenden Zeitpunkt auf, was dann wiederum dafür führt, dass IT-Dienste unterbrochen werden oder gar Arbeitsausfälle mit entsprechenden Verdienstausfällen daraus resultieren.
Unser Autor Ron Stock, ist beim Microsoft Windows Escalation Team tätig und wird dort in seiner Arbeit fast täglich mit der Aufgabe betreut, solche Crash-Vorfälle zu untersuchen. Mit den Ergebnissen dieser Untersuchungen versucht er dann möglichst schnell entsprechende Aktionspläne zu erstellen, die dafür sorgen sollen, dass diese Fälle in den betroffenen Firmen nicht mehr auftreten.
Diese Aufgabe ähnelt in vielen ihrer Aspekte durchaus der Vorgehensweise, wie sie durch die Experten der CSI-Teams in den diversen amerikanischen Fernsehserien angewendet werden: Diese Untersuchungsspezialisten nutzen ebenfalls diverse Low-Level-Methoden, um den Schuldigen eines Verbrechens aufzuspüren. Wie Ron Stock aus seiner täglichen Praxis weiß, sind auch bei seinen „Ermittlungen“ die Spuren mikroskopisch klein: So kann es sich beispielsweise um ein einziges Bit handeln, dass auf den Wert „1“ gesetzt wurde, wo der ausführende Programmcode aber unbedingt den Wert „0“ verlangt.
Erschwerend kommt bei seinen Untersuchungen hinzu, dass der „Verursacher“ eines solchen Falls häufig schon lange verschwunden ist und nur einen „beschädigten“ Speicherbereich hinterlässt. Dadurch wird beispielsweise die Suche nach einem Treiber, der einen solchen Absturz möglicherweise verursacht, noch einmal deutlich erschwert. Wie können es also nun die Administratoren schaffen, die „Schuldigen“ auszumerzen, die einen korrupten Speicherbereich und damit zumeist einen Systemabsturz verursacht haben?
Der Kampf beginnt: Werkzeuge und die Pool-Memory-Architektur
In diesem zweitteiligen Artikel stellt Ron Stock die Werkzeuge vor, die das Support-Team bei Microsoft bei der Bekämpfung von Speicherbeschädigungen (Memory Corruption) im Bereich des Kernel-Speichers einsetzt. Diese Probleme werden in einem Großteil der Fälle von fehlerhaften Treibern verursacht, die leider nur in den seltensten Fällen einen deutlichen Hinweis auf ihre Identität hinterlassen. Da dieses Thema sehr komplex ist, mag es auf Anhieb nicht sofort einsichtig sein, warum das Microsoft-Team ganz bestimmte Tools für solche Fälle „verordnet“. Hier sollen dieser Artikel und sein zweiter Teil besonders den Administratoren eine Hilfestellung bieten, die in ihren Systemumgebungen dafür verantwortlich sind, dem Management nach solchen Vorfällen einen entsprechenden Plan zur Vermeidung solcher Probleme vorzulegen.
Ebenso soll es mit Hilfe dieser Artikel möglich sein, einen großen Teil der Verwirrung zu lichten, die um dieses Thema immer noch herrscht. Allerdings müssen wir in diesem Zusammenhang auch ausdrücklich erwähnen, dass eine sehr große Zahl von anderen Gründen existiert, die solche Abstürze hervorrufen können, wir uns hier aber auf einige der Werkzeuge konzentrieren werden, die vom Microsoft Support eingesetzt werden. Diese Tools kommen immer dann zum Einsatz, wenn das Team Abstürze analysieren muss, die von einer Memory Corruption im Speicherbereich des Kernels verursacht wurden.
Bevor wir uns aber in diese Werkzeuge und deren Einsatz vertiefen, sollen hier die Architektur-Grundlagen der Speicher-Pools noch einmal kurz dargestellt werden, weil dieses Hintergrundwissen die Erläuterung der einzelnen Werkzeuge deutlich vereinfacht. Ein Großteil des Speicherplatzes, der von den Treibern verwendet wird, allokiert das System von den beiden Speicher-Pools des Windows-Systems: Sie werden als Paged Pool und Nonpaged Pool bezeichnet. Natürlich gibt es auch Ausnahmen von dieser Regel, deren Diskussion aber weit über den Umfang und den Zweck dieses Artikels hinausgehen würde. Wie es der Namen des Speicherbereichs bereits vermuten lässt, garantiert das Betriebssystem, dass der Speicher, der vom Nonpaged Pool benutzt wird, immer im physikalischen Hauptspeicher des Systems vorhanden ist. Teile des Paged Pool können hingegen zu jedem Zeitpunkt auf die Festplatte ausgelagert (swap out) werden, sie befinden sich dann also im Bereich des virtuellen Hauptspeichers.
Die Werkzeuge verstehen: Von Speicherseiten und deren Größen
Wer die Ausgaben der verschiedenen Werkzeuge besser verstehen will, muss sich immer wieder vor Augen führen, dass diese Speicher-Pools in kleinere Bereiche unterteilt werden, die als Pages (Seiten) bezeichnet werden. Dabei existieren große und kleine Speicherseiten. Während eine kleine Page eine Größe von 4 KByte besitzt, sind die großen Speicherseiten auf einer x64-Plattform 2 MByte und auf einer x86-Plattform 4 MByte groß. Wenn allerdings auf einem x86-Windows-System die Option für die sogenannte Physical Adress Extension (PAE – Erweiterung der physischen Adresse) aktiviert ist, wird die Größe der großen Speicherseite auf 2 MByte reduziert. Beide dieser Seitengrößen besitzen in der Praxis durchaus ihre Vorteile, wir werden aber im weiteren Verlauf des Artikels in der Regel von den kleineren 4 KByte Seiten ausgehen, wenn wir von Speicher-Pages sprechen.
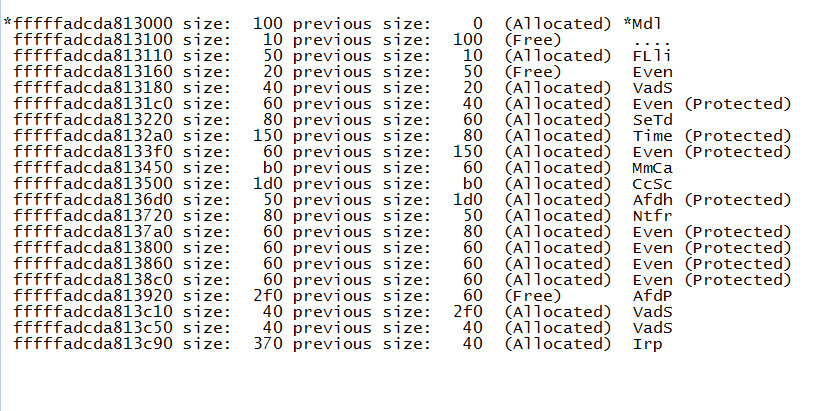
Eine solche Speicherseite wird dann durch aktuelle Zuteilungen weiter unterteilt. Diese werden Zuteilungen von den Treibern veranlasst, die für sich Hauptspeicherbereiche anfordern. In Bild 1 ist eine zufällig ausgewählte Speicherseite aus dem Bereich des Nonpaged Speichers zu sehen, die der Autor als Dump-Datei herausgeschrieben hat. Dieser Speicher-Dump stellt ein Beispiel für eine kleine Speicherseite mit einer Größe von 4 KByte dar. Um diese Ausgabe zu erzeugen, hat der Autor das Kommando !pool verwendet, dass der Microsoft Debugger (windbg.exe) bereitstellt. Dieses Werkzeug ist Teil der Microsoft Debugging Tools, die bei Microsoft auf einer speziellen Seite zu diesem Thema zum Download bereitstehen.
Das Global Escalation Service Team von Microsoft setzt diese Software hauptsächlich ein, wenn es darum geht solche Speicherprobleme und –fehler aufzuspüren und zu beseitigen. Die Ausgabe in Bild 1 repräsentiert eine einzelne 4 KByte Seite des Nonpaged-Speichers. Jede Spalte in dieser Ausgabe stellt einen Speicherblock dar, der entweder der Seite zugewiesen (allokiert) oder von ihr freigegeben wurde. Die meisten der Blöcke in diesem Beispiel sind allokiert, und durch die Bezeichnung am rechten Rand der Anzeige (wird hier als „Tag“ bezeichnet) ist es möglich, ungefähr zu bestimmen, welcher Prozess diesen Block besitzt. Wenn ein Treiber eine Anfrage startet, um Speicher aus dem Pool zu allokieren, reicht er die Größe des angeforderten Speicherbereichs zusammen mit einer vier Zeichen großen Bezeichnung (dem „Tag“) weiter. Sowohl dieser Tag als auch die Größe des angefragten Speicherblocks werden in einer speziellen Struktur zur „Buchhaltung“ vorgehalten, die als Pool-Header bezeichnet wird. Sie wird dann am Anfang jedes festgelegten Bereichs abgelegt.
Die Struktur beinhaltet auch den Block für die aktuelle und die vorherige Größe. Diesen Block kann der Speichermanager dazu verwenden, den Inhalt der Speicherseite für Wartungsaufgaben leicht und einfacher zu durchsuchen: Dazu gehört beispielsweise die Aufgabe, aneinander grenzende freie Blöcke zu einem großen freien Bereich zu vereinigen. Der Bereich, der direkt an den Pool-Header anschließt, ist möglicherweise aus der Sicht der Treiber, die Speicher belegen wollen, der wichtigste Bereich: Dies ist der eigentliche Speicherbereich für die Daten der Speicherseite.
Der Ort des Verbrechens: Suche nach den Spuren des Treibers…
Nachdem wir nun gezeigt haben, wie der Memory-Manager die Speicherbereich in einem Pool grundsätzlich verwaltet, wollen wir nun einen Blick darauf werfen was passiert, wenn sich Softwarefehler einschleichen und eben jene unangenehmen „blauen Bildschirme“ verursachen. Zu den Fehlern, die bei den Treibern mit am häufigsten auftreten, gehört das Schreiben über den reservierten Speicherbereich hinaus. Die Treibersoftware legt dabei Daten in einem Hauptspeicherbereich ab, der ihr nicht zugeordnet ist, und überschreibt dabei im schlimmsten Fall die Daten einer anderen Anwendung oder gar des Betriebssystems. Wie im vorherigen Absatz dargestellt wurde, befindet sich vor dem Bereich mit den eigentlichen Daten immer der Pool-Header mit den entsprechenden Informationen zu dem bestimmten Bereich. Schreibt eine Treibersoftware also in den nächsten allokierten Bereich hinein, beschädigt sie in der Regel den Pool-Header dieses Bereiches. Versucht nun der Memory-Manager etwas später diesen beschädigten Pool-Header auszulesen, wird das System höchstwahrscheinlich unter Meldung einer der beiden folgenden Fehler Check-Codes abstürzen:
Bug Check 0x19: BAD_POOL_HEADER
Bug Check 0xC2: BAD_POOL_CALLER
Die Parameter dieser Fehlertests werden von Microsoft auf MSDN ziemlich gut
dokumentiert. Wirft der Administrator einen Blick auf die ersten beiden Parameter, so bekommt er Informationen zum Status des Fehlers – allerdings erhält er dabei keine Daten darüber, welcher fehlerhafte Treiber dieses Problem nun verursacht hat. Bevor wir dann endlich auf die Werkzeuge zur „Beseitigung“ solcher Treiber eingehen, wollen wir dieses Szenario noch etwas erweitern: Wir setzen dazu die Ausgabe des Debuggers ein, wie sie in Bild 1 zu sehen ist. Dabei gehen wir davon aus, dass der Treiber, der den VadS-Pool an der Adresse fffffadcda813c50 nutzt, über den Pool-Header des Bereichs IRP geschrieben hat, der bei der Adresse fffffadcda813c90 festgelegt ist. Der fehlerhafte Treiber schreibt dann weiter in den Datenbereich von IRP hinein.
Setzt der Treiber, der den Bereich IRP verwendet, nun diese beschädigten Daten ein, so ist die Gefahr sehr groß, dass das gesamte System instabil wird. Was aber an dieser Situation noch viel schlimmer ist: Der Treiber, der den IRP-Pool besitzt, scheint bei einem Absturz dann der Verantwortlich für dieses Problem zu sein, weil sich dieser Treiber zum Zeitpunkt des Systemabsturzes sehr wahrscheinlich auf dem Stack befinden wird! Der Fehler Check-Code kann in diesem Fall unterschiedlich aussehen, in Abhängigkeit davon, wie der IRP-Pool die beschädigten Daten verwendet hat. So kann das System beispielsweise den Fehler:
STOP 0x0000001e
ausgeben, wenn der Treiber des Irp-Pools versucht, auf den beschädigten Wert wieder als Zeiger zu verweisen, und die Software nicht auf den Wert zugreifen kann. Aber was passiert, wenn es trotzdem möglich ist auf die „kaputte“ Adresse zuzugreifen und der Treiber dann Daten an diese zufällige Adresse im Speicher schreibt? Dann wandert der Fehler in einen anderen Speicher-Pool oder gar in einen kritischen Teil der Kernel-Struktur hinein. Warum wir all die Grundlagen in Rahmen diese Artikels so ausführlich darstellen? Diese Grundlagen und ganz besonders auch das letzte Beispiel zeigen doch
sehr deutlich, wie schwer es auch für einen absoluten Systemprofi sein kann, den Weg zu dem verursachenden Treiber zurück zu verfolgen, wenn kein eindeutiger Pfad in Richtung des Schuldigen weist.
Die Jagd geht immer weiter
Natürlich scheint der vorgestellte Fall klar: Ein Systemadministrator könnte bei der zuvor geschilderten Konstellation einfach auf den VasD-Pool als die schuldige Partei deuten und dieses Problem zu den Akten legen. Aber man sollte diesen Fall einmal unter praktischen Aspekten weiterdenken: Es könnte ja durchaus so ablaufen, dass der VasD-Pool vom Memory-Manager bereits wieder freigegeben wurde, und dass gleich nach der Beschädigung des Irp-Pool durch VasD ein anderer Treiber den Block in seinem Bereich schon wieder allokiert hat. Das bedeutet, dass der eigentliche Besitzer von VasD schon lange verschwunden ist, was das Problem zu einem „Cold Case“ werde lässt.
In solchen Fällen hat dann der Special-Pool seinen Auftritt. Dieser Special-Pool wurde mit Windows NT und dem Service Pack 4 eingeführt und dient dazu, solche Treiber, die Speicherbereiche korrumpieren, dann auch in Echtzeit zu fangen. Dies geschieht dabei mittels sogenannten Schutzseiten (guard pages), die rund um den allokierten Bereich "aufgestellt" werden. Dieses Mechanismus beruht auf der Idee, dass man Treiber, die über den von ihnen reservierten Speicherplatz hinausschreiben, auf diese Art und Weise dazu zwingt, in die Schutzseiten hineinzuschreiben. Das würde das System zu einem sofortigen Absturz bringen, bei dem sich dann definitiv der schuldige Treiber ganz oben auf dem Stack befindet.
Damit besitzt der Administrator dann aber einen eindeutigen Beweis, welcher Treiber die Probleme verursacht: Die Amerikaner nennen diesen Ansatz sehr bildhaft den „smoking gun approach“ – der Böse wird also noch mit dem rauchenden Revolver in der Hand erwischt. Ron Stock wird in den nächsten Wochen einen zweiten Artikel zu diesem Thema erstellen, in dem er unter anderem auch erläutert, wie dieser Special-Pool-Mechanismus aufgebaut ist und wie er sich in das Betriebssystem einfügt.


