Cohesity konsolidiert Sekundärspeicher
20. Juli 2018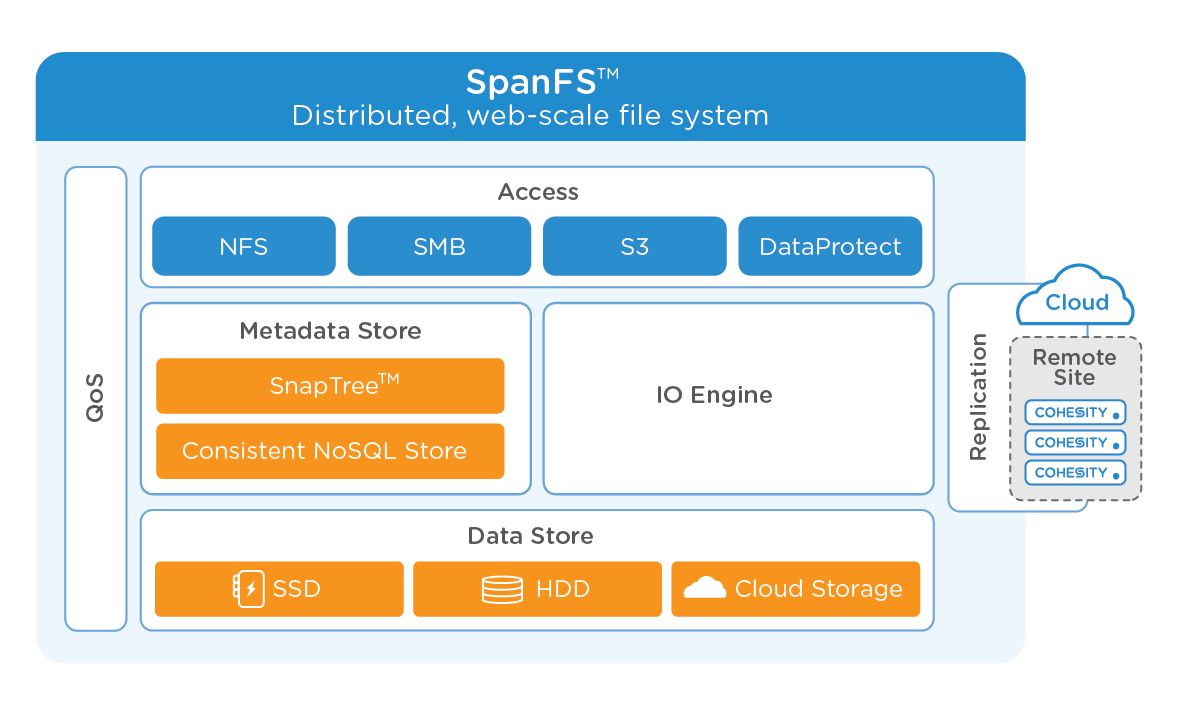
Im Storage-Bereich lassen sich etwa HCI-Lösungen (Hyperkonvergente Infrastrukturen) einsetzen, Cloud-Ressourcen direkt auf den Client-Systemen anbinden (Onedrive, iCloud-Drive, AWS S3), oder die Unternehmen beziehen ihre Apps direkt aus der Cloud (Amazon WorkSpaces, Microsoft Azure). All diese Lösungsansätze für den Secondary Storage lassen sich durch den Einsatz eines globalen Dateisystems kombinieren und optimieren: Falls ein einziges Dateisystem sowohl auf den lokalen Systemen, als auch auf VMs (virtuelle Maschinen), Containern, HCI-Lösungen und sonstigen Cloud-Ressourcen als „Unterbau“ eingesetzt wird, profitieren die Administratoren und Mitarbeiter in den IT-fremden Fachabteilungen. Cohesity stellt mit „SpanFS“ eine Lösung bereit mit folgenden Features bereit: Eine globale Deduplizierung mit variabler Blockgröße, eine effektive Snapshot-Technologie (SpanTree), sowie eine automatische und auf Performance optimierte Verteilung der Nutzdaten auf die unterschiedlich „schnelle“ Massenspeichermedien komplettieren diese Lösung.
Starre und monolithische Speichersysteme werden im Cloud-Zeitalter immer mehr zum Auslaufmodell. In der Vergangenheit befand sich der sekundäre Speicher (Massenspeicher, beispielsweise in Form von Hard Disk Drives, HDDs) direkt im selben Blech die auch die Compute-Ressourcen. Sprich es wurden Server mit den passenden Komponenten kombiniert (CPU, DRAM, HDDs, Netzwerk) und diese untereinander vernetzt. Die Speichermedien waren per „Direct Attached Storage, DAS“ an den einzelnen Servern angebunden, über Schnittstellen wie ATA/ATAPI oder SCSI.
Durch die veränderten Anforderungen (besonders im Hinblick auf die stetig steigenden Speichermengen) bildeten sich die Datensilos: Dabei handelt es sich um Serversysteme, Storage-Arrays oder Appliances, die mit möglichst vielen Massenspeichermedien bestückt wurden. Beispielsweise haben Storage-Spezialisten wie Netapp, Dell EMC, HP oder IBM. Diese lassen sich beispielsweise über entsprechende Netzwerkleitungen und den passenden Protokollen (FibreChannel, Ethernet, iSCSI, SAN) mit relativ geringen Overhead ansprechen. Allerdings ist die Bandbreite von den zur Verfügung stehenden Netzwerkleitungen limitiert. Daher setzen die Systembetreuer meist auf mehrere, redundant ausgelegte Netzwerkverbindungen. Das soll auf der einen Seite die zur Verfügung gestellte Bandbreite erhöhen, zum anderen auch HA bieten (Hochverfügbarkeit). Durch die „langen Verbindungswege“ sowie mehrere Netzwerkknoten, Switches oder Gateways und die jeweiligen Switche müssen zudem gewisse Einbußen bei der Reaktionszeit in Kauf genommen werden (Latenz).
Aktuell kehrt sich der Trend um, sprich seit einigen Jahren werden Systeme eingesetzt, bei denen alle Komponenten (CPU, DRAM, Massenspeicher und Netzwerk) wieder in einem Knoten verbaut werden: HCI, Hyperkonvergente Intrastrukturen. Prominente Beispielse sind zum Beispiel –Datacore oder Nutanix. Mehrere dieser Knoten werden danach per Netzwerk zusammengefasst, und diese bilden einen entsprechenden Cluster. Dieser „zukunftsweisende Rückschritt“ hat mehrere Gründe: Zum einen sind inzwischen die Anforderungen an Bandbreite und Latenz deutlich gestiegen – besonders was die Anbindung der Massenspeichermedien angeht. Waren in der Vergangenheit etwa mechanische Festplatten mit 15.000 U/min das „Nonplusultra“, wurden diese von Flashspeichermedien überholt. Eine moderne 15.000er HDD für den Enterprise-Bereich überträgt etwa 250 MByte/s, die Zugriffzeit liegt dabei etwa bei im Bereich von fünf Millisekunden (ms). Diese Werte übertreffen bereits Solid State Drives (SSDs), die für den Consumer-Bereich hergestellt wurden (knapp 600 MByte/s bei einer Zugriffszeit von unter einer ms).
Noch „schnellere“ Flashspeicher auf Basis von NVMe (Non-Volatile Memory Express) erreichen (je nach verwendeter Hardware-Schnittstelle) doch deutlich besserer Werte. Derartige Speichermedien benötigen eine gewisse Nähe zu den Compute-Komponenten, sowie passend konfigurierte Schnittstellen. Der Performance-Gewinn basiert darauf, dass jeder Knoten im HCI-Cluster über entsprechend „schnell“ angebundene Speichermedien verfügt, und die Jobs auf den gesamten Cluster verteilt werden. Auf diese Weise lässt sich die parallel bereitgestellten Storage-Performance) effizient nutzen. Bei diesen Hyperkonvergenten Infrastrukturen stellen die Hersteller entweder die Software bereit, die auf (beinahe) beliebige Server installiert werden kann, oder bieten entsprechende Appliances, bei der Hardware und Software kombiniert sind.
Allerdings werden Cloud-Ressourcen immer häufiger eingesetzt. Diese sollten in ein derartiges Cluster-Konzept mit eingebunden werden. Dazu sind unterschiedliche Lösungsansätze denkbar. Beispielsweise bieten die großen Cloud Anbieter (Google, Microsoft, Amazon) entsprechende Schnittstellen (APIs) zur Anbindung und Implementierung dieser Ressourcen. Besonders die Punkte Hochverfügbarkeit, Skalierbarkeit und die hohe Datenmenge machen es immer schwieriger die aktuellen (und künftigen) Anforderungen an die IT-Infrastruktur abzudecken. An dieser Stelle springt Cohesity in die Bresche, mit dem Dateisystem „SpanFS“ und der zugehörigen Snapshot-Lösung „SnapTree“ lassen sich lokale Storage-Systeme, HCI sowie Cloud-Ressourcen effizient nutzen. Dabei skaliert die Lösung beinahe linear, auf diese Weise lassen sich Systeme und Ressourcen (beinahe) beliebig hinzufügen oder entfernen (Bild 1).
Secondary Storage
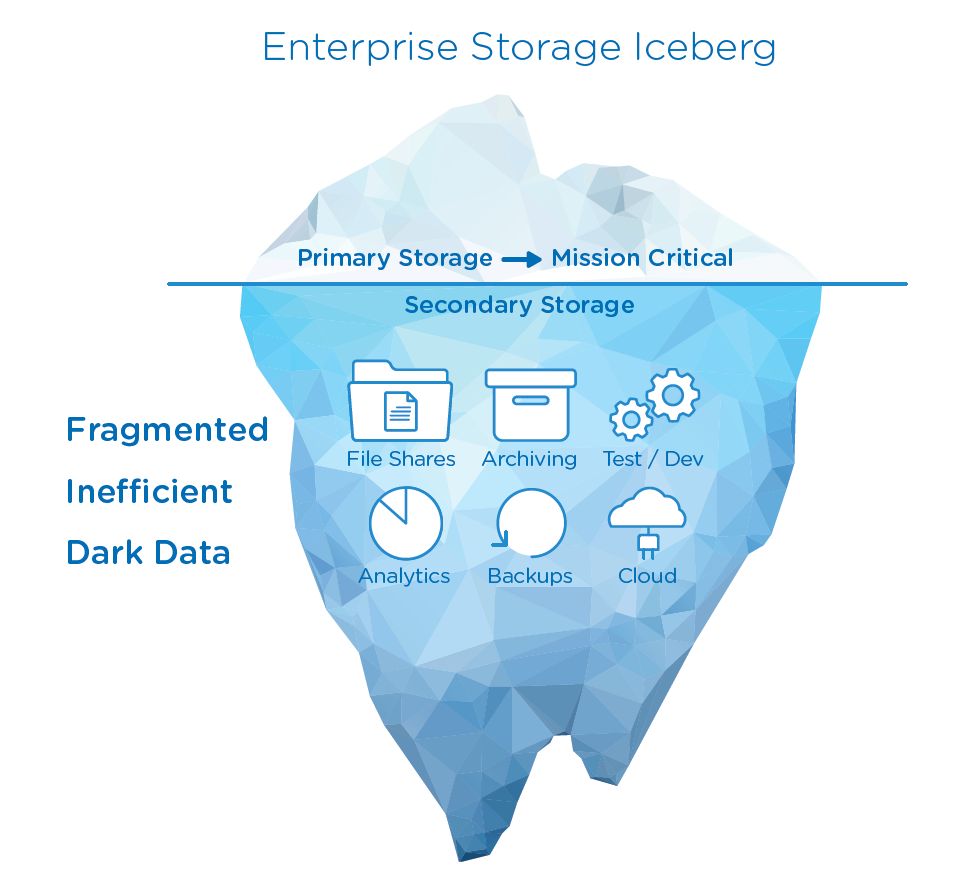
Im Kontext der Speicherarchitektur wurde bislang klar zwischen Primär- und Sekundärspeicher unterschieden: Als Primärspeicher verstand man den flüchtigen Speicher der IT-Systeme (beispielsweise CPU-Cache oder DRAM). Mit Sekundärspeicher wurden persistente Storage-Ressourcen bezeichnet, etwa Festplatten, SSDs, RAID-Systeme, NAS-Geräte, oder Datensilos auf SAN-Basis (Storage Area Network). Bei Cohesity möchte man mit der Definition „Primary Storage“ und „Secondary Storage“ dagegen die Wortbedeutung neu prägen. Dabei soll deutlich gemacht werden, ob es sich um Daten handelt, die aktuell im Unternehmen genutzt werden (Primärspeicher), oder ob es sich um Backup- und Archivdaten, selten genutzten Dateifreigaben oder etwa Testdateien handelt (Sekundärspeicher). Mit dem primären, „heißen Daten“ sind folglich etwa aktive Datenbanken oder ERP- und CRM-Systeme gemeint. Bei den sekundären, „kalten Daten“ dagegen selten oder wenig genutzte Daten, wie zum BeispielSnapshot-Kopien der eigentlichen Produktionsdaten.
Globales Dateisystem
Cohesity setzt bei der Konsolidierung seines „Secondary Storage“ auf ein gemeinsames Dateisystem. Auf diese Weise soll die Vernetzung von Cloud-Lösungen und lokalen (Server-) Ressourcen gelingen. Denn durch den Einsatz des „globalen Dateisystems“ ergeben sich viele Vorteile. Denn die vorhandenen Daten können ohne weitere Schnittstellen auf die unterschiedlichen Knoten (Nodes) im Cluster verteilt werden. Damit lassen sich sowohl HCI-Systeme, Storage-Silos, VMs auf „On-premises-Systemen“ oder auch Cloud-basierte VMs sowie Cloud-Storage-Angebote ansprechen. Zudem lassen sich Techniken wie Deduplizierung (dedup) für den gesamten Datenbestand einsetzen.
Das besondere beim Cohesity-Ansatz: Beim Deduplizieren der einzelnen Datenblöcke ist keine feste Blockgröße vorgegeben. Vielmehr optimiert SpanFS die Größe der einzelnen Datenblöcke – je nach vorliegenden Rohdaten. Dabei umgeht Cohesity das folgende Problem: Wird eine „große“ Blockgröße für die Deduplizierung gewählt, werden nur wenige identische Blöcke aussortiert, allerdings entfällt so ein Großteil des Verwaltungsaufwands. Nutzt man sehr kleine Blöcke, können zwar sehr viele Datenhappen dedupliziert werden, allerdings sinkt die Performance (Schreib- Lesegeschwindigkeit und Latenz). Beim SpanFS dagegen ist die Blockgröße variabel, somit kann für jede Art von Daten das Optimum gewählt werden. Dies wird im Hintergrund von SpanFS automatisch durchgeführt. Deduplikation ist vor allem dort interessant, wo viele identische Datenblöcke erwartet werden. Ein gutes Beispiel hierbei wäre eine virtualisierte Arbeitsumgebung, bei der eine große Anzahl an Windows-VMs bereitgestellt werden. Denn viele dieser Daten (Windows- und Systemverzeichnisse) sind quasi „identisch“, oftmals unterscheiden sich die VMs nur anhand einiger Nutzdaten.
Ein weiter wichtiger Punkt wird deutlich, wenn die Systembetreuer einen Blick auf die Verteilung der Daten werfen: Neben den eigentlichen, aktuellen Nutzdaten setzt sich der Datenbestand zu einem Großteil aus „Alt-Daten“ wie etwa Archiv- oder Backup-Datensätzen zusammen. Dabei kann es vorkommen, dass die aktuellen Nutzdaten nur etwa 20 Prozent ausmachen, während der Großteil (bis zu 80 Prozent) auf diese „Alt-Daten“ beziehungsweise Sekundärdaten (nach Definition von Cohesity) entfallen. Man spricht an dieser Stelle sogar vom „Daten-Eisberg“ (Bild 2), denn bei diesem ist auch nur etwa ein Fünftel sichtbar, während der Großteil sich unter Wasser – und damit außerhalb des Sichtbereichs befindet. Allerdings zählen die Systembetreuer auch weitere Ordner, LUNs, Cloud- und Testdaten zum Sekundären Speicher. An dieser Stelle sind etwa selten benötigte Dateien und Ordner auf Netzlaufwerken, virtuelle Festplatten von testweise angelegten VMs oder eine redundante Kopie der Backup-Archivdateien im „Zweit- oder Drittstandort (Cloud)“ gemeint.
Bei den meisten „Legacy-Speicherstrukturen“ treffen zwei oder mehrere Generationen aufeinander. Denn die „klassischen“ Enterprise-Storage-Infrastrukturen mit Datensilos im eigenen Rechenzentrum bieten in der Regel eine zentrale Verwaltung (sowohl bei der Verteilung von Ressourcen, als auch bei den Berechtigungen), und sind meistens mit den Protokollen „NFS (Network File System)“ oder „SMB (Server Message Block)“ angebunden. Allerdings lassen sich diese Silos nur innerhalb gewisser Grenzen skalieren, und dies meist nicht linear. Sprich wenn mehr Speicher benötigt wird, lassen sich mehr Festplatten verbauen, diese teilen sich allerdings in der Regel die zur Verfügung gestellte Bandbreite. Und diese lässt sich in den meisten Fällen nicht ohne weiteres linear (mit)skalieren. Auch wenn „plötzlich“ weniger Speicherplatz benötigt werden sollte, werden die Systembetreuer nicht wieder HDDs aus den Storage-Systemen entfernen. Denn dies ist entweder nicht so leicht möglich – beispielsweise, wenn die HDDs Teil eines RAID-Verbunds sind. Daher wird dieser Aufwand meist nicht betrieben. Die ungenutzten HDDs verbleiben weiter Im Speichersystem und sorgen an dieser Stelle für höhere Energie- und Betriebskosten.
Aktuell setzen sehr viele Unternehmen auf weitere Ressourcen, ein typisches Beispiel (Cloud-Storage als Archiv- oder Backupspeicher) wurde bereits angesprochen. Die Vorteile von Cloud-Speicher wie es etwa von Amazon (etwa mit Amazon Web Services, AWS S3) vertrieben liegt dabei auf der Hand: Benötigen die Firmen weiteren Speicherplatz, wird dieser umgehend bereitgestellt (und berechnet), dabei skaliert diese Lösung (beinahe) beliebig – sowohl nach „oben“ als auch nach „unten“. Wird zu einem späteren Zeitpunkt weniger Storage benötigt, so kann dies mit Cloud-Lösungen einfach und effektiv realisiert werden — ohne dass die Administratoren die Daten erst sicherheitshalber sichern, RAID-Systeme auflösen, Datenträger ausbauen, die verbleibenden neu konfigurieren, auf den Raid-Rebuilds warten, die Volumes erzeugen, neu formatieren und die Nutzdaten wieder zurückspielen müssen. Auf der anderen Seite nutzen die Cloud-Anbieter proprietäre Schnittstellen (vergleiche OneDrive, iCloud oder Amazon S3) und lassen sich nicht ohne weiteres in die IT-Infrastruktur der Unternehmen einbinden.
Die Kombination aus den genannten Vorteilen bietet das Dateisystem von Cohesity, dabei ist die volle Integrationsfähigkeit gegeben. Das System lässt sich mit lokalen secondary storage sowie passenden Cloud-Ressourcen skalieren – und bietet sowohl NFS-, SMB- als auch S3-Unterstützung. Auf diese Weise lassen sich „alte“ Datensilos (etwa SAN-Systeme) im Unternehmen ersetzen.
Wichtige Features
Neben den bereits vom Dateisystem abgedeckten Punkten werden zusätzliche Sicherheitsfunktionen in den Unternehmen benötigt. An vorderster Stelle dürfte hier die Datensicherheit stehen. Denn was hilft das beste Storage-System, wenn es nach einem Hardware- oder Softwarefehler zum Datenverlust kommt? Folglich müssen sich die Systembetreuer Gedanken machen, auf welche Weise die bereitgestellten Dateien möglichst vollständig abgesichert werden können. An dieser Stelle wurde in der Vergangenheit auf das Prinzip „3-2-1“ sowie spezielle Backup-Medien gesetzt. Sprich man fertigt mindestens drei Kopien der zu sichernden Daten an, verteilt diese auf mindestens zwei Standorte, und bewahrt mindestens eine Kopie auf „Offline-Medien“ für den absoluten Notfall an einem sicheren Ort auf. Sollten nun beispielsweise Verschlüsselungstrojaner sämtliche Systeme chiffrieren, und beispielsweise ebenfalls Zugriff auf (online gespeicherte) Backup-Datensätze erlangen, können die Systembetreuer mit den passenden Offline-Medien (externe HDDs, Magnetbänder) trotzdem einen entsprechenden Restore vornehmen. Dieses Prinzip behält auch im „Cloud-Zeitalter“ seine Gültigkeit. Cohesity bietet an dieser Stelle ebenfalls die Möglichkeit, Bandlaufwerke oder andere externe Speicherlösungen mit einzubinden.
Aber ein starres Backup-Konzept allein sorgt (noch) nicht für eine möglichst sichere und effektive IT-Infrastruktur. Daher werden in der Regel sogenannte „Snapshots“ erzeugt – sprich Abbilder eines bestimmten Zustands. Dieses Konzept wird beispielsweise im Bereich der Virtualisierung häufig genutzt (so lassen sich VMs auf Knopfdruck in einen vorher gesicherten Zustand versetzen). Das ermöglicht eine Art „Lite-Restore-Funktion“. Dies ist nützlich, wenn etwa ein Administrator testweise bestimmte Funktionen am Betriebssystem verändert hat, und diese mit einem Knopfdruck wieder rückgängig machen möchte. Auf diese Weise muss nicht ein zeitraubendes Komplett-Backup eingespielt werden, sondern es wird „einfach“ der passende Snapshot eingespielt. Dieses Vorgehen macht nicht nur bei VMs Sinn, sondern wird auch bei einem Dateisystem interessant. Löschen bestimmte Mitarbeiter beispielsweise aus Versehen wichtige Daten, muss nicht extra ein Backup eingespielt werden, auch hier reicht es aus, den entsprechenden Snapshot zu laden.
Beim SpanFS handelt es sich um ein „Distributed File System“, somit werden die Verwaltungs- und Managementfunktionen nicht an einer zentralen Stelle konzentriert, sondern (gleichmäßig) auf alle Systeme im SpanFS verteilt. Auf diese Weise fallen potentielle Flaschenhälse heraus, das Dateisystem, die Management-Funktionen sowie die Nutzdaten sind vielmehr auf alle Netzwerkknoten verteilt.
Aktuelle Dateisysteme müssen mit einer großen Anzahl an unterschiedlichen Medientypen und Speichertechnologien zurechtk0ommen. Bei SpanFS werden die Daten (je nach Klassifizierung) zwischen den verfügbaren SSDs (Solid State Drives), HDDs und dem Cloud-Speicherplatz automatisch aufgeteilt. Es wird ein globaler Index erzeugt, dabei werden sowohl die Dateien selbst als auch die Metadaten indiziert, ebenfalls ist eine entsprechende Suchfunktion integriert. Ebenfalls ist eine Verschlüsselung (AES-256) implementiert, die Lösung ist zudem Multi-Mandanten-fähig. Dazu lassen sich bestimmte Speicherbereiche separieren, passende Verschlüsselungs-Keys erzeugen und eine rollenbasierte Zugangsbeschränkung einsetzen.
SnapTree
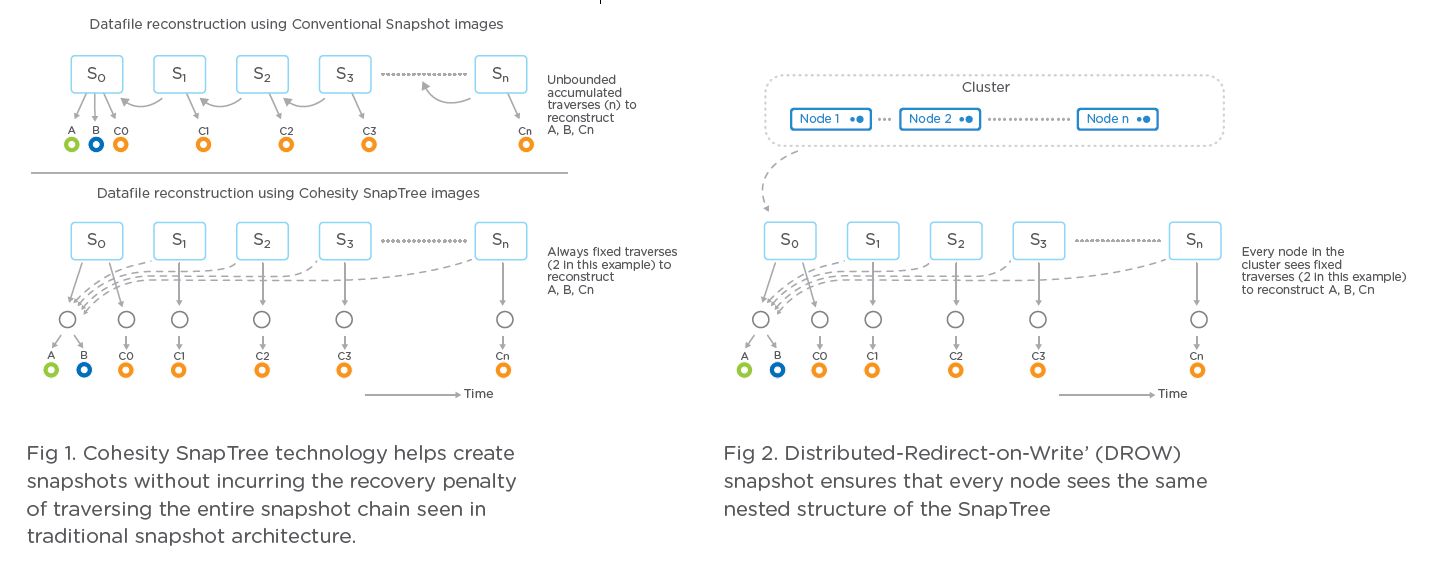
Bei SnapTree handelt es sich um eine Snapshot-Technologie, die für das Zusammenspiel mit SpanFS optimiert wurde. Klassische Snapshots bauen immer auf der Vorgänger-Version auf (vergleiche inkrementelle Backups). Sprich es wird zunächst Snapshot-01 erzeugt, dann Snapshot-02, danach Snapshot-03 und so weiter. Jede Version basiert dabei auf der vorangegangenen. Schleicht sich an dieser Stelle ein Fehler ein (beispielsweise wird Snapshot-02 gelöscht oder verändert), so können die folgenden Snapshots unter Umständen nicht korrekt verwendet werden. Zudem erhöht sich der Overhead, etwa wenn man einen Snapshot am Ende der Liste wiederherstellen möchte (etwa Snapshot-108).
Cohesity ändert dabei das Vorgehen beim Anlegen der Snapshots. Denn jeder Snapshot bezieht sich nicht auf die (Kette der) vorangegangenen Versionen, sondern immer auf den „Initialen Snapshot“, beziehungsweise auf die Originaldateien. Auf diese Weise lassen sich Snapshots schneller und zuverlässiger wiederherstellen. Damit ähnelt das Vorgehen beim Anlegen der SpanTree-Snapshots eher dem einer differenziellen Sicherung (Bild 3).
Fazit
Neben lokalen On-Premise-Serversystemen müssen Cloud-Ressourcen, diverse Netzwerk-Appliances sowie „klassische“ Datensilos in den meisten Unternehmen unter einem Hut gebracht werden. Zur Vereinfachung dieser heterogenen IT-Infrastrukturen können die Administratoren unterschiedliche Konzepte verfolgen. Bei der Aktualisierung der IT, sowie der Umstellung auf Cloud-Ressourcen sollten die Systembetreuer einen Blick auf die Lösung von Cohesity werfen. Denn mit dem globalen, web-basierten Dateisystem können die Systembetreuer sowohl On-Premises-Server, virtuelle Maschinen (sowohl im eigenen RZ, als auch in der Cloud) zusammen mit Cloud-Speicherplatz kombinieren.
Dank der effektiven Verwaltung, den Features bei der Deduplizierung, dem modifizierten Snapshot-Funktionen und dem prakischen „Auto-Tiering“ werden die benötigten Daten mit der benötigten Performance und Bandbreite vorgehalten, während „kalte“ Archiv- oder Backupdateien in den kostengünstigen Cloud-Speicher (etwa AWS S3) verschoben werden. Dies wird nach der Erstkonfiguration vom System selbstständig dem laufenden Betrieb angepasst. Somit fungieren die Systembetreuer „nur“ noch als Aufpasser, und können sich anderen Aufgaben widmen. Weitere Informationen sind auf der Webseite von Cohesity zu finden…


