PDF-Malware: Probleme, Eigenschaften & Schutz, Teil 1
18. September 2011Verschiedenen Hersteller zu denen auch Microsoft gehört, haben bereits einige Male versucht alternative Dateiformate einzuführen, durch die eine „Vormachtstellung“ des Adobe-eigenen PDF-Formats gebrochen werden sollte. Bisher war keinem dieser Versuche Erfolg beschieden, so dass Administratoren auch weiterhin mit den PDF-Dateien und deren Sicherheitsproblemen leben müssen. Unser Autor zeigt in diesem zweiteiligen Bericht die Schwachstellen auf und gibt Tipps, was Administratoren gegen diese Bedrohung tun können.
Es kann kein Zweifel daran bestehen, dass PDF zu den populärsten Dateiformaten auch über Plattformgrenzen hinweg zählt: Nicht nur auf den Windows-, sondern auch auf den meisten MacOS- und Linux-Plattformen wird sich mindestens eine Anwendung finden, die zum Lesen dieser Dateien dienen kann. Sowohl die eigentliche Seitenbeschreibungssprache PDF als auch die meisten Reader-Programme, die zur Verfügung stehen, sind grundsätzlich so entwickelt und umgesetzt worden, dass sie die Ausführung von bösartigem oder unerwünschten Programmcode verhindern.
Trotzdem tauchen immer wieder Berichte über Schwachstellen in den diversen PDF-Readern und –Anwendungen auf und entsprechend präparierte PDF-Dokumente werden immer wieder im Netz und via Mail verteilt. Unser Autor Didier Stevens zeigt in diesem Beitrag, wie „bösartige“ PDF-Dokumenten zweifelhaften Programm-Code ausführen können und welche Mittel ein Administrator besitzt, um seine Anwender vor diesem Problem zu schützen. Viele dieser Tipps und Tricks können auch problemlos auf andere Anwendungen übertragen werden, die beispielsweise mit Microsoft Office-Dokumenten arbeiten.
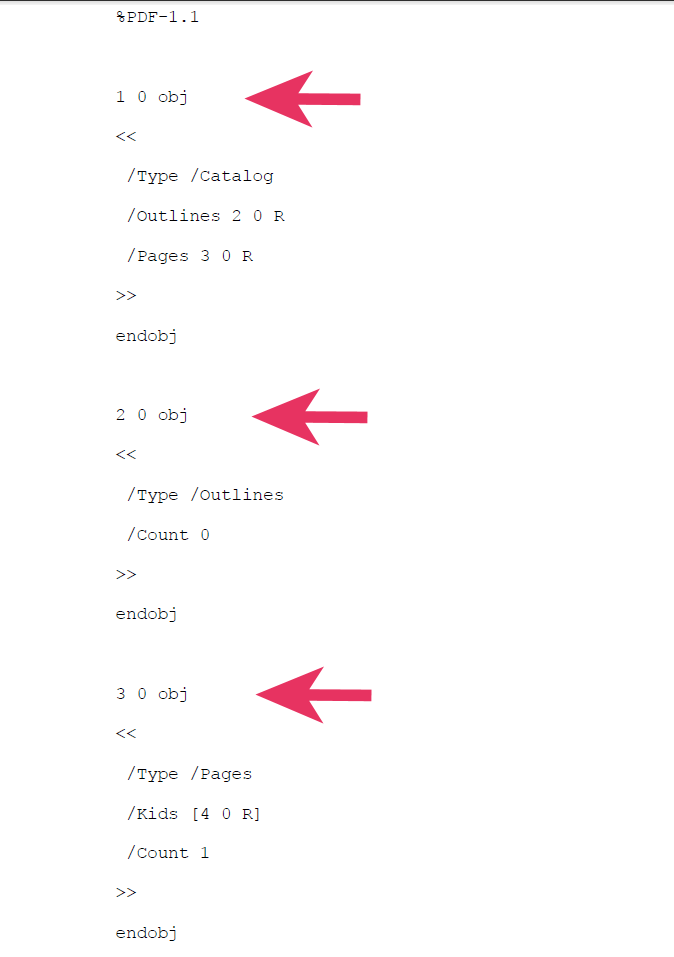
Im Bild 1 zeigen wir Ausschnitte aus dem Listing eines einfachen PDF-Dokuments, in dem sich PDL-Code (Program Design Language – eine Art Pseudocode in normaler Sprache, der zur Entwicklung und zum Design von Methoden und Prozeduren verwendet werden kann) befindet, der den allseits bekannten Text „Hello World“ ausgibt.
Unser Autor hat dieses Listung so angelegt, dass es nur die wichtigsten Elemente enthält, die ein PDF-Dokument benötigt. Zudem hat er in dem Beispiel nur ASCII-Zeichen verwendet, so dass unsere Leser den Inhalt der Datei leichter nachvollziehen können.
Grundlagen PDF: Einfacher Aufbau mittels Baumstruktur
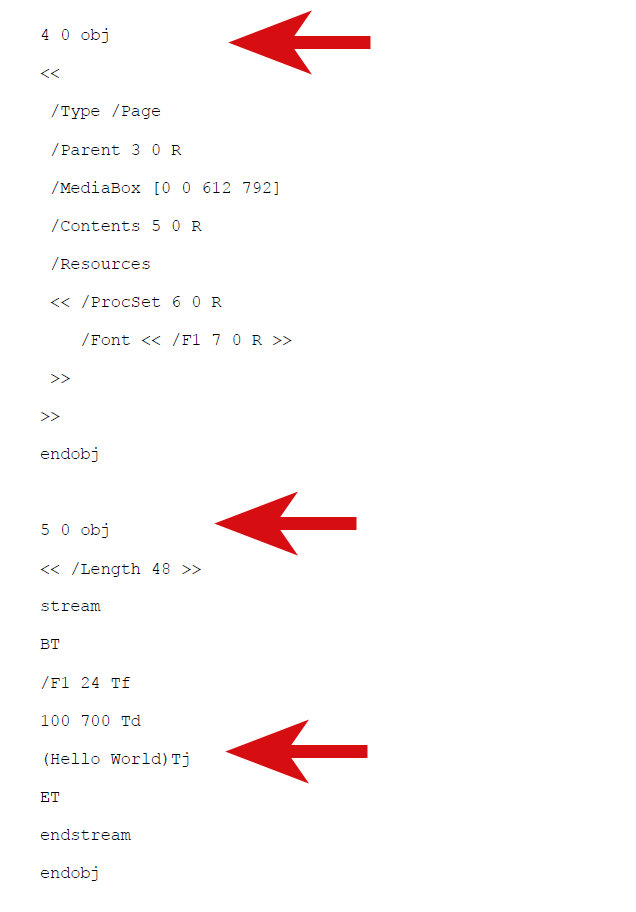
Grundsätzlich besteht ein PDF-Dokument aus einer baumartigen Struktur von Objekten. Diese beinhalten all die Anweisungen, die der PDF-Reader benötigt, um die Dokumentenseite zu rendern. In unserem Beispiel ist das Root-Objekt 1 (1 0 object – im Bild 1 durch einen Pfeil gekennzeichnet). Dieses Objekt befindet sich an der absoluten Position 12 des Dokuments. Das Root-Objekt verweist auf die Sammlung von Seiten, die sich in einem PDF-Dokument befinden (beispielsweise, object 3). Unser Beispieldokument beinhaltet nur eine einzige Seite, die in Objekt 4 (object 4, siehe Bild 2) definiert wird. Im Bild 2 ist dann auch der eigentliche Text, der Inhalt des Dokuments zu sehen, der in Objekt 5 ablegt ist.
Der Text „Hello World“ ist dort in unserem Beispiel ebenfalls mit einem Pfeil gekennzeichnet (diese Pfeile gehören nicht zur PDF-Datei, sondern sollen hier nur das Auffinden der wichtigen Punkte vereinfachen) und wird in Klammern eingeschlossen. Die anderen Schlüsselworte, die hier zu sehen sind, definieren Texteigenschaften, wie beispielsweise den Font, der zu verwenden ist, oder die Stelle auf der Seite, an der dieser Text erscheinen soll. Dieses Beispiel einer PDF-Datei ist auch deshalb sehr leicht zu durchschauen, da hier kein komprimierter Text verwendet wird. Normalerweise verwenden alle PDF-Dateien komprimierten Text, so dass ihr Quelltext ohne die richtigen Werkzeuge nicht lesbar ist.
Fast jeder Reader besitzt auch eine JavaScript-Engine
Sowohl die PDF-Beschreibungssprache als auch die meisten Programme zum Lesen von PDF-Dateien unterstützen JavaScript. So können Skripte direkt in ein PDF-Dokument eingebunden werden, die ein PDF-Reader dann direkt interpretiert und abarbeitet. Die JavaScript-Engine, die ein PDF-Reader dazu verwendet, besitzt in der Regel Einschränkungen, was ihre möglichen Interaktionen mit dem Betriebssystem angeht. So gibt es dabei beispielsweise kein JavaScript-Statement oder auch keine JavaScript-Funktion, die ein Lesen von einer „böswilligen“ Datei oder gar das Schreiben in eine solche Datei erlauben würde. JavaScript kommt in PDF-Dateien häufig dann zum Einsatz, wenn es darum geht, Formulare zu verarbeiten, um auf diese Weise zum Beispiel Summe oder Steuersätze direkt in der Datei zu errechnen.
Es gibt immer einen Weg: Die Manipulation der PDFs
Wie kann es dann also möglich sein, dass die Autoren von Schadsoftware immer wieder Wege finden, um zum Beispiel ein Windows-System mittels einer manipulierten PDF-Datei zu infizieren und zu beschädigen? Sie tun das, indem sich die entsprechenden Anwendungen zum Lesen von PDF-Dateien, wie etwa den bekannten Adobe PDF-Reader, aktiv nach entsprechenden Schwachstellen untersuchen. Solche Schwachstellen (vulnerabilities) werden häufig in eigentlichen Engine zum Bearbeiten der PDF-Dateien aber auch in der implementierten JavaScript-Engine gefunden.
So wurde zum Beispiel im Jahr 2008 eine solche Schwachstelle in der Funktion „util.printf“ innerhalb der JavaScript-Engine des Adobe PDF-Readers entdeckt. Der Hersteller hat diesen Fehler in der Zwischenzeit mit Hilfe eines Patches behoben, so dass er in den aktuellen Versionen des PDF-Readers nicht mehr auftaucht.
Die Funktion „util.printf“ dient normalerweise dazu, ihr mitgegebene Argumente zu verarbeiten und dann eine formatierte Zeichenkette nach Maßgabe dieser Argumente auszugeben. Aber wenn diese Funktion vor dem Patch mit einer Reihe von ganz spezifischen Argumenten versorgt wurde, wurde ein Fehler im internen Code der Funktion direkt angesteuert. Dadurch verhielt sich die Funktion bei der Übergabe dieser speziellen Argumente nicht mehr so, wie es die Entwickler eigentlich vorgesehen hatten, was an diesem internen Programmfehler lag.
Anstatt den Text zu formatieren und eine Rückmeldung über die Ausführung dieser Aufgabe zu geben, machte der Programmfluss es durch den Fehler möglich, dass die Ausführung des Codes nun außerhalb des Programms durchgeführt wurde. Dies geschah dabei an einer Adresse, an der kein Programmcode existierte. Ein Windows-Programm, das versucht nicht existierenden Programmcode auszuführen, generiert automatisch einen Fehler im System. Dieser Fehler hat dann wiederum sofort den Prozess des Adobe-Readers beendet.

Wie der Programmcode „umgeleitet“ werden kann…
Die Möglichkeit, die Programmkontrolle an eine willkürliche Stelle im Hauptspeicher „umzuleiten“ ist so etwas wie der „Heilige Gral“ der Programmierer von Schadsoftware. Dies ist genau der Hebel, den sie benötigen, um ein ansonsten normales Programm angreifbar durch den eigenen Programmcode zu machen. Malware-Programmierer mit großer Erfahrung sind dabei sogar dazu in der Lage, die Adressen zu denen der Programmcode dann verzweigt, komplett unter Kontrolle zu bekommen. Dies wird als Extended Instruction Pointer Control, oder auch EIP-Control bezeichnet.
Der EIP oder auch „Erweiterter Befehlszähler“ ist der Befehlszähler der CPU, wobei es sich hier um ein Register handelt, das auf die Adresse im Hauptspeicher zeigt, an der sich der entsprechende ausführbare Programmcode befindet. Programmierer, die entsprechende Schadsoftware entwickeln, setzen zunächst den von ihnen geschriebenen Schadcode an diese Adresse in den Hauptspeicher, um dann die Schwachstelle in einer Anwendung oder dem Betriebssystem auszunutzen, so dass die Ausführung des Programms zu genau dieser Adresse verzweigt.
Trotzdem wird man solche sogenannten Exploits mit einer totalen EIP-Kontrolle in schadhaften PDF-Dokumenten recht selten „in the wild“ finden. Als „in the wild“ werden dabei solche Schadprogramme bezeichnet, die sich ungehindert direkt im Internet ausbreiten und ihre Schadroutinen ausführen. Es existieren aber zudem auch sogenannte „Proof-of-Concept“-Schadprogramme, die sich nicht ausbreiten, sondern nur zeigen sollen, dass eine bestimmte Attacke auch grundsätzlich funktionieren könnte. Viel öfter sind in „freier Wildbahn“ jedoch PDF-Schadprogramme zu finden, die eine teilweise Kontrolle über EIP erlangen.
Die Autoren solcher Malware sind durchaus dazu in Lage, einen Exploit zu entwickeln, der dann zu einer ganz besonderen Adresse im Speicherbereich verzweigt, die außerhalb des normalen Programmcodes liegt. Aber sie können in der Regel eine solche Schadroutine aber nicht so anlegen, dass sie zu jeder beliebigen, willkürlich gewählten Adresse im Hauptspeicher verzweigt, so dass sie dann die komplette Kontrolle erlangen.
Bösartiger Code wird mittels "Heap-Spray" in Stellung gebracht
Sie verwenden stattdessen eine Technik in JavaScript, die als Heap-Spray bezeichnet wird. Sie kommt zum Einsatz, um den bösartigen Programmcode im Hauptspeicher zu installieren. Dabei füllt diese Technik den dynamischen Speicherbereich des verwundbaren Programms, den sogenannten Heap-Speicher, mit bösartigem Shellcode. Bei diesem Shellcode handelt es sich um ein kleines Programm, das in Maschinensprache geschrieben ist, und an jeder beliebigen Stelle des Hauptspeichers korrekt ausgeführt werden kann.
Solcher Shellcode ist relativ klein, wenn er in den üblichen bösartigen Angriffen über PDF-Dateien zum Einsatz kommt. Typischerweise führt ein solcher Maschinencode die folgenden Aufgaben aus:
- Er lädt ausführbaren Programmcode mittels eines HTTP-Requests von einem Web-Server im Internet nach.
- Dann speichert er diese Datei im System32-Systemordner ab und
- führt dann diese heruntergeladenen Datei aus.
Der Trick dabei: Dieser Shellcode besitzt an sich keine Programmteile, die an sich bösartigen oder schädlichen Programmcode ausführen: Es handelt sich hier nur um einen Download-Programm, das dann beispielsweise den wirklichen Trojaner vom Netz nachlädt. Durch diese Vorgehensweise stehen den Malware-Autoren auch viel mehr Möglichkeiten offen: So können sie zum Beispiel das eigentliche Schadprogramm auf dem Web-Server immer noch und immer wieder modifizieren, nachdem sie die infizierte PDF-Datei im Internet verbreitet haben. Ein solches Schadprogramm – bei dem es sich zum Beispiel um einen Trojaner handeln kann, infiziert dann schließlich den PC des Anwenders und macht ihn unter Umständen dadurch zum aktiven Mitglied eines Bot-Netzes.
Wir werden diesen Beitrag demnächst hier auf NT4Admins fortsetzen: Dann wird Didier Steven auch die verschiedenen Schutztechniken der modernen Windows-Systeme diskutieren und zeigen, wie sie gegen die Gefahren helfen können, die durch PDF-Dateien drohen, die mit Schadcode belastet sind.

