Lösung der LUN-Problematik in virtualisierten Umgebungen, Teil 1
22. Juli 2015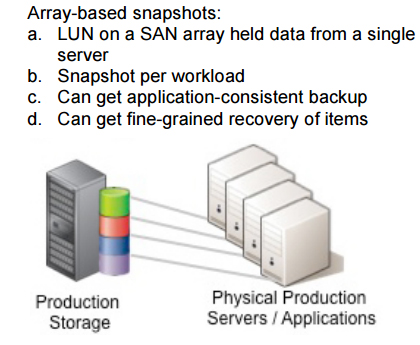
Heutzutage ist es Standard, virtualisierte IT-Umgebungen einzusetzen. Doch die Unternehmen handeln sich damit nicht nur Vorteile ein – vor allem im Storage-Bereich sind einige Klimmzüge anzustellen, um einfacher Verwaltungs- und Sicherungsfunktionen bereitzustellen. Hier können vor allem „VM-zentrische“ Modelle (Virtual Machine) punkten, wie sie mit dem Omnicube von Simplivity bereit stehen.

Die Virtualisierungstechnik hat im IT-Bereich an vielen Stellen die Arbeit vereinfacht. Damit haben sich die Server besser auslasten lassen, neue virtuelle Systeme sind schneller angelegt worden– aber auch über VDI (Virtual Desktop Infrastructure) wurden Optimierungen erzielt und letztendlich Kosten gespart. Doch was das Schützen der Daten angeht, ist die Aufgabenstellung leider nicht besser geworden. Es sind zwar einige Storage-Systeme verfügbar, die mit der „Virtualisierungsgeneration“ besser zurechtkommen – einige davon sind Software-basierte Lösungen nach dem Konzept „Software Defined“. Sie adressieren die durch die Virtualisierung neu dazu gekommene Komplexität, indem sie die Datenschutzfunktionalitäten auf der Basis von Virtuellen Maschinen (VMs) und nicht mehr auf der Basis von „Volumes“ angehen.
Früher hatte ein logisches Volume in einem SAN-Array die Daten von einem einzigen Server enthalten. Zu dieser Zeit waren Snapshots für den Schutz dieser Daten eine großartige Sache. Denn ein derartiger Snapshot war nichts anderes als ein „eingefrorenes Abbild“ der Festplatten eines Servers. Darauf konnte man nach einem Systemproblem schnell zurückgreifen. Oder man war in der Lage, daraus die benötigten Daten wiederherzustellen, wenn zum Beispiel ein Benutzer angerufen hatte, weil er das Excel-Sheet mit den Unternehmensergebnissen aus dem letzten Monat mit denen des aktuellen Monats überschrieben hatte. Damit die Snapshots auch noch konsistent zu den verschiedenen Applikationen waren, kamen Mechanismen wie VSS (Volume Shadow Copy Service bei Windows) oder aber Linux-/Unix-Skripts zum Einsatz. Damit wurden alle Schreibzugriffe auf die Datenbank ausgeführt und alle Puffer auf Festplatte geschrieben, ehe der Snapshot auf den Platten abgelegt wurde. Damit war der komplette Informationsinhalt auf den Harddisks konsistent. Ein typisches Array konnte auch die Daten für ein Volume, die zu einem einzelnen Server gehörten, replizieren und sie dabei auf einen Ausweichstandort übertragen. Je nachdem, wie wichtig die Informationen des betreffenden Servers waren, fand die Replikation umso öfter statt. Das war ein ausgezeichnetes Mittel, um die Ausfallsicherheit zu erhöhen.
Doch bei der Servervirtualisierung wurden auch all deren Daten in einem einzigen Datenspeicher abgelegt. Wenn fünf, zehn oder noch mehr VMs auf einem Virtualisierungs-Host konsolidiert wurden, sind auch all deren Daten in dem Datenspeicher abgelegt – also auf einem einzigen SAN-Volume oder einer LUN (Logical Unit Number). Je größer die Anzahl der virtuellen Server anwuchs, umso schwieriger wurde es, für jeden eine individuelle Lun anzulegen und diese vielen LUNs dann auch sauber zu verwalten. Auch wenn man damit zurechtkommen würde, Tausende von LUNs anzulegen und zu verwalten, so macht einem die Virtualisierungsplattform meist wieder einen Strich durch die Rechnung. Bei vSphere zum Beispiel gibt es eine Limitierung die lautet: nur 255 LUNs werden in einem Cluster unterstützt.
VM-zentrisch ist gefragt
Wenn der Systembetreuer nun alle Daten in Datenspeicher zusammenführt, verliert er die Fähigkeit, dass das Storage-System die Daten von einem einzelnen – virtuellen – Server schützen kann. SAN-Arrays und viele NAS-Appliances sind nur in der Lage, den Speicher auf der Ebene von Volumes zu verwalten. Wenn bei einem derartigen System ein Snapshot von einer VM gemacht wird, dann werden auch alle Änderungen von allen anderen VMs in diesem Datenspeicher auf die Festplatten geschrieben. Damit wird bei Konfigurationen mit vielen VMs auf einem Host auch sehr viel Speicherplatz benötigt – mit einem eher überschaubaren Nutzen.
Ein weiteres Problem ergibt sich in Bezug auf die Konsistenz. Man kann eigentlich keinen Applikations-konsistenten Snapshot von mehreren (virtuellen) Servern zu einem Zeitpunkt anfertigen. Es erweist sich in der Praxis als viel zu schwierig, dass mehrere Applikationen, die auf verschiedene virtuelle Server verteilt sind, alle zur selben Zeit eine „Ruhepause“ für das Flushen der Puffer einlegen und dann den Snapshot ausführen.
Als Ausweg für dieses Dilemma kann man eine Konfiguration wählen, in der nur eine Applikation, von der konsistente Snapshots gemacht werden sollen, in einem Datenspeicher abgelegt wird. Oder aber man fertigt mehrere Snapshots an, wo allerdings immer nur eine Applikation zu diesem Zeitpunkt konsistent gesichert wird. Doch bei all diesen Ansätzen werden sehr viele Daten geschrieben – sprich der Speicherbedarf steigt massiv an. Das führt dann bei der Replikation zu einem zweiten Standort – etwa um Ausfallsicherheit zu garantieren – zu entsprechend massiv erhöhten Anforderungen an die Bandbreite für die Anbindung.
Wer nun denkt, dass die Snapshot-Funktionalität, die auf der Ebene der Hypervisoren (wie etwa bei vSphere oder bei Hyper-V) bestehen, einen besseren Ersatz bietet, der wird schnell erkennen: Bei dieser Art der Snapshots handelt es sich nur um einen sehr eingeschränkten Ersatz. Bei einem Hypervisor-Snapshot werden immer nur Informationen protokolliert, die zwischen einem Snapshot und seinem direkten Vorgänger „angefallen“ sind. Damit sind diese Snapshots nur in speziellen Fällen nützlich: Etwa wenn man eine Backup-Quelle benötigt, bei der ein Snapshot nur für eine begrenzte Zeitspanne existiert. Je länger ein Snapshots existiert, umso größer wird das Protokoll und umso langsamer der Zugriff auf die entsprechende VMDK-Datei.
Der Nachteil in Bezug auf die Performance wirkt sich noch schlimmer aus, wenn auf Volumes mehrere Generationen von Snapshots liegen. Auch das Löschen eines Snapshots kann zur Folge haben, dass sehr viel Ein-/Ausgabeoperationen zu den Festplatten auftreten, denn der Hypervisor reicht die Aktualisierung an die Vorgängerdate durch und aktualisiert entsprechend.
Im Verlauf der Zeit haben die Hersteller von Storage-Arrays verschiedene Mechanismen benutzt, um Snapshots anzufertigen. Beim „Copy-On-Write“ (COW) wird die Aktion verlangsamt, da ein jeder Schreibzugriff in drei Operationen aufgesplittet wird: Es werden die alten Daten gelesen, dann werden die alten Daten in den Snapshot geschrieben und dann zuletzt werden die neuen Daten geschrieben. Die herkömmlichen Storage-Systeme, die COW-Snapshots einsetzen, waren für „drehende Disks“ konzipiert. Bei derartigen Disk-basierten Systemen wird immer versucht, dass man Daten, die logisch beieinander liegen, auch physisch nacheinander ablegt, so dass sie quasi sequentiell gelesen werden können.
Bei modernen Speichersystemen, die Flash-basierten Speicher für bestimmte Speicherbereiche (oder auch für alle beim Flash Only Storage) verwenden, sind die „Random IO“-Zugriffe genauso schnell wie sequentielle. Daher ergibt sich kein Vorteil, wenn man logisch zusammengehörige Daten auch physikalisch benachbart ablegt. Um die bestmögliche Durchsatzleistung aus Flash-Speicher herauszuholen, virtualisieren diese Systeme den Speicher. Sie verwenden Zeiger und andere Metadaten, um zu verfolgen, welche physischen Blöcke zu jedem logischen Block gehören.
Bei einem derartigen Storage-System ist ein Volume eigentlich nichts anderes, als ein Satz von Metadaten, die beschreiben, welche logischen Datenblöcke das Volume ausmachen. Da die Metadaten eines typischen Volumes weitaus weniger Umfang haben als die Daten selbst, wird das Erstellen einer Kopie zu einer schnellen Aktion – die somit so gut wie keine Auswirkung auf die Performance des Storage-Systems nach sich zieht.
Bei jedem Snapshot, der erzeugt wird, handelt es sich um eine unabhängige Kopie der Metadaten – was einige Vorteile bringt: Anders als beim COW-Mechanismus und bei den Protokoll-basierten Snapshots gibt es keine Kette oder keinen Baum von „abhängigen“ Snapshots, auf die man sich beziehen müsste oder die man aktualisieren müsste, wenn Anwendungen auf das Volume zugreifen wollen. Das bedeutet für die Systemadministration: Man kann mehrfache Snapshots anlegen und Snapshots für lange Zeitspannen behalten, ohne dass man negative Auswirkungen auf die Performance befürchten muss. Wenn man nicht mehr diese Performance-Einbußen im Storage-Bereich zu befürchten hat, können Unternehmen Snapshots auch als ihre erste – und wichtigste – Sicherungsebene verwenden und zum Beispiel alle täglich anfallenden Wiederherstellungs-Requests aus diesen Snapshots bedienen.
Die Kopien der Metadaten lassen sich zudem noch als Read-Write-Replikate verwenden. Bei dieser Art von Replikaten können die Test– und Entwicklungsteams mit einer vollständigen und vollkommen unabhängigen Version der Produktivdatenbank arbeiten.
Auch wenn die auf Metadaten basierenden Snapshots viele Vorteile haben – in einer virtualisierten Umgebung gibt es dasselbe Problem wie alle Snapshots, die auf Volume-Ebene ansetzen. Sie verfügen über eine zu geringe Granularität. Wer einen Snapshot eines SAN-Volumes anlegt, um die Informationen einer einzigen VM zu schützen, der schießt mit Kanonen auf Spatzen – und wird auch sehr schnell viel Speicherkapazität verbrauchen.
Daher wurden Storage-Systeme konzipiert, die sich besonders gut für den Einsatz in virtualisierten Umgebungen eignen. Anstelle nur eine „dumme“ LUN für den Hypervisor bereitzustellen, verwalten diese Systeme ihre eigenen Dateisysteme und gewähren dem Hypervisor den Zugriff über File-Sharing-Protokolle wie NFS oder SMB 3.0. Damit steht ihnen genügend Kontextinformation zur Verfügung, um die Datenschutzfunktionalitäten – inklusive der Snapshots – auch für virtuelle Festplatten oder virtuelle Maschinen bereitzustellen.
Hier sind alternative Lösungen gefragt, wie sie zum Beispiel mit der Omnicube-Reihe von Simplivity verfügbar sind. Im zweiten Teil dieser Artikelreihe wird gezeigt, welche Vorteile die VM-zentrische Speicherverwaltung bringen kann.


