Cloud Bursting löst die Spitzenlastproblematik
21. Juli 2014
Unternehmen wollen ihre Profitabilität und Wettbewerbsfähigkeit steigern. Das lässt sich erreichen, wenn sie mit weniger Aufwand mehr „erlösen“. Wie weit sich die Effizienz von Rechenzentren steigern lässt, hängt davon ab, wie weit ein Unternehmen die Anforderungen an die Verarbeitung und die Bereitstellung von Diensten von der statischen, darunter liegenden Infrastruktur lösen kann. Denn dann können die Anwendungen entsprechend der Nachfrage reale Standorte überspannen.
Mit Hilfe der Cloud Bursting-Architektur von F5 Networks lässt sich diese Abstraktion realisieren. Doch dazu ist eine hybride Cloud-Architektur nötig.
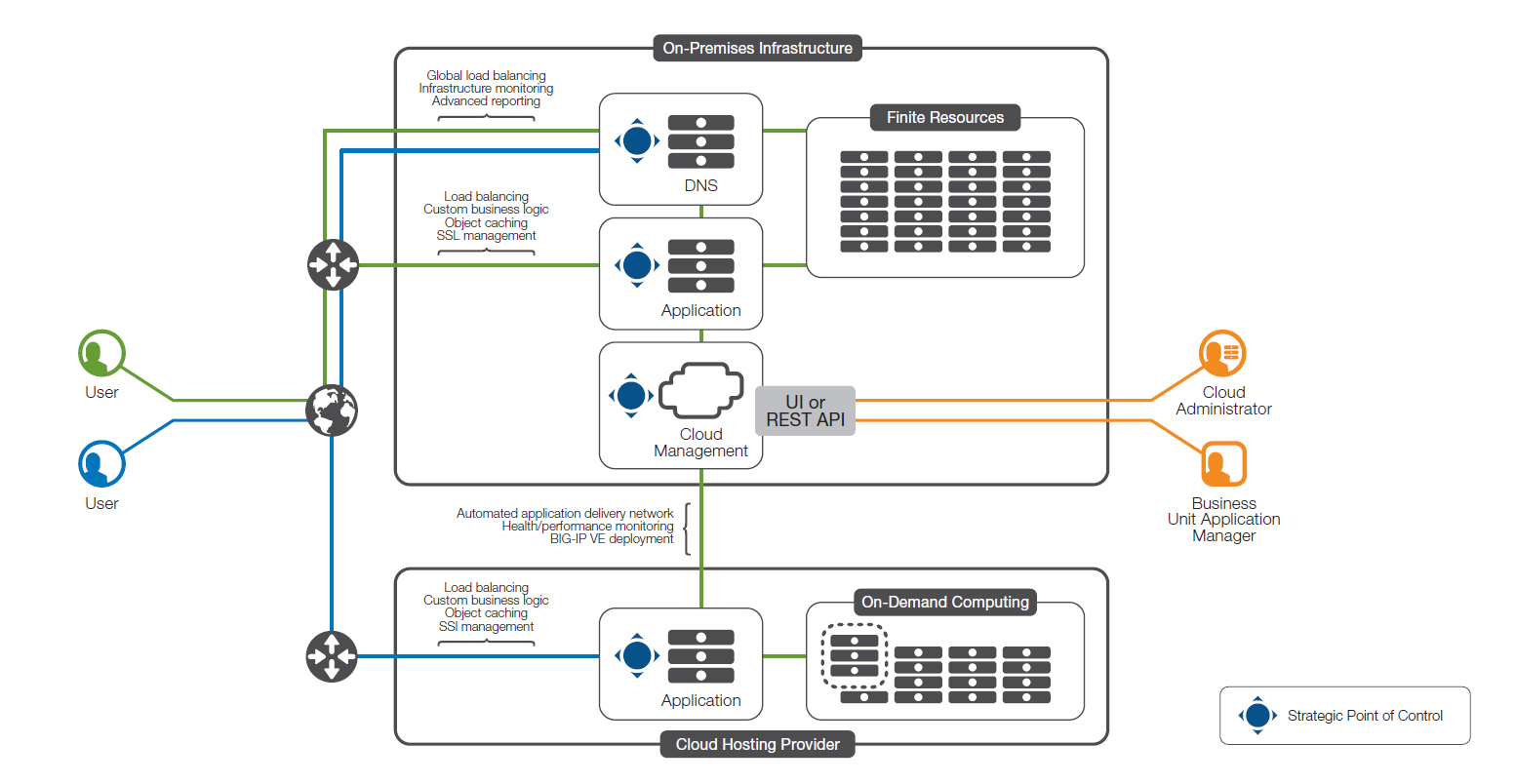
Diese Ausgangssituation dürfte vielen IT-Verantwortlichen bekannt sein: Im eigenen Unternehmen laufen die Anwendungen in der eigenen IT-Umgebung. Doch man möchte auch die Cloud als Bestandteil der IT-Infrastruktur ausprobieren, doch nicht unbedingt die kritischen Anwendungen in die „Wolke“ geben.
Üblicherweise geht der Schritt zuerst in die private Cloud – sprich die Cloud-Technik wird im eigenen Unternehmen eingesetzt. Daraus lassen sich bereits einige Vorteile ableiten – etwa wenn die Benutzer über ein Self-Service-Portal sich gewisse Dienste selbst zuteilen können oder auch nur ihr Kennwort selbst neu setzen dürfen.
Erst im zweiten Schritt liebäugeln Unternehmen dann mit einer Hybrid Cloud – ein Teil verbleibt dabei nach wie vor im eigenen Rechenzentrum, der andere wird zu einem Dienstleister/Cloud-Anbieter ausgelagert. Doch dabei stellt sich die Frage, wie die Infrastruktur im Unternehmen ausgelegt sein muss, dass man auch eine hohe Verfügbarkeit erreicht. Denn die eigene Infrastruktur sollte ja mit der des Dienstleisters zusammenpassen.
Hier hat sich ein Unternehmen in erster Linie zu entscheiden, welche Applikationen es auslagern kann und wie die Kapazitätsplanung oder -auslastung im eigenen Rechenzentrum davon profitieren. Bei der Migration einer (oder mehrerer Applikationen) in die Cloud (auch als „Cloud Migration“ bezeichnet) steht meistens ein permanentes Auslagern einzelner Anwendungen oder Dienste an.
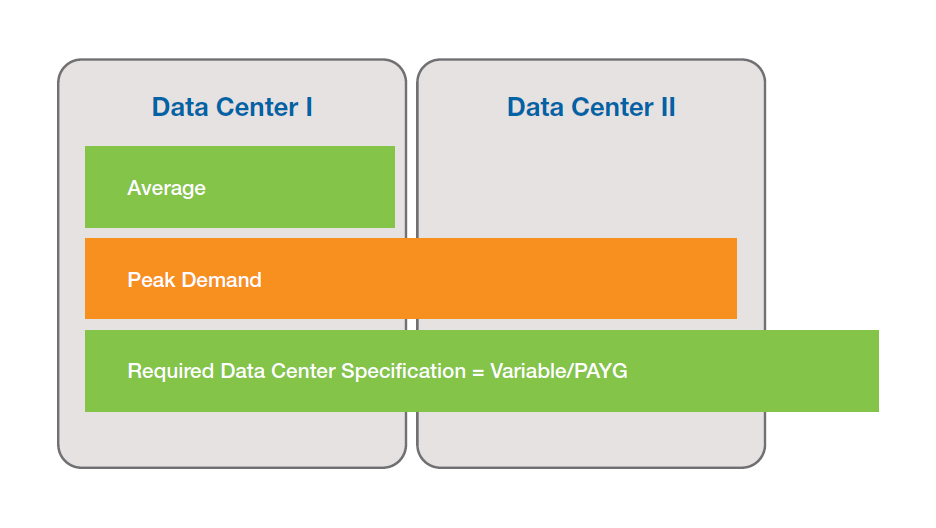
Beim Cloud Bursting ist die Technik dahinter quasi identisch. Doch die Triebfeder ist eine andere, denn die Devise in diesem Fall lautet: „Ich mache überwiegend alles selbst in meinem Rechenzentrum. Doch ich möchte vorbereitet sein, Spitzenlasten etwa bei saisonalen Einflüssen durch mein Business, extern abfedern zu können. Damit kann ich das Rechenzentrum günstiger konzipieren. Ich decke nur den durchschnittlichen Bedarf selbst ab, gebe die Spitzenlasten an einen externen Provider.“
Damit lassen sich grundlegende Einschränkungen – etwa wie viel Strom, man in sein Rechenzentrum maximal „hinein“ kommt – ebenfalls berücksichtigen. Das betrifft nicht nur bestehende Rechenzentren, sondern auch die Unternehmen, die ihr Rechenzentrum „auf der grünen Wiese“ planen können. Auch hier stellt sich die Frage, wie groß – und somit auch wie überdimensioniert – ist die Konfiguration anzugehen.
Hochverfügbarkeit stellt ihre eigenen Anforderungen
Wer einen Application Delivery Controller etwa auf einem BIG-IP-System einsetzt, der weiß genau, wo sich die Applikation „aufhält“. Ändert sich die Konfiguration einer Anwendung, etwa durch eine Orchestrierungs-Einheit zum Beispiel in einer vCloud, dann muss das unterbrechungsfrei funktionieren. Es gilt die Vorgabe, dass die extern angebundenen Anwender davon nichts mitbekommen. Sie sollten sich auch nicht damit befassen müssen, dass sich die IP-Adresse für den Server, auf dem die Anwendung läuft, geändert hat.
Üblicherweise wird bei einer Migration der betreffende Service bei einem Cloud-Provider hochgefahren und dann, ab einem gewissen Zeitpunkt x, werden die Benutzer auf dieses System aufgeschaltet. Das bezieht sich auf zusätzliche Benutzer, die eine neue Session beginnen. Die bestehenden Sessions von Anwendern sollte man auf den internen Systemen zunächst weiterlaufen lassen. Erst bei einer neuen Session werden diese dann umgeleitet.
Bei hoher Last muss das Orchestrierungs-Tool diesen Zustand rechtzeitig bemerken. Dazu werden verschiedene Parameter (CPU-Auslastung, Festplattenzugriffe, etc.) in den virtuellen Maschinen (mit den laufenden Applikationen) geprüft. Im Falle eines Falles gilt es dann, eine Entscheidung zu treffen: Es sind weitere Services hochzufahren, und die werden dann zum Beispiel in der Cloud bereitgestellt. Diese Veränderung in der Applikationsinfrastruktur muss das BIG-IP-System erfassen. Dazu ist eine offene Programmierschnittstelle des Systems nötig, wie etwa ein REST-basiertes API (Application Programming Interface).
Über eine derartige Schnittstelle kann das Orchestrierungs-Tool dem BIG-IP-System mitteilen, dass sich die IP-Adresse mit dieser und jener Applikation geändert hat und dass sie jetzt unter einer neuen Adresse erreichbar sind. Dann übernimmt das BIG-IP-System – genauer der Applikations-Controller – diese Info in die eigene Konfiguration und kann das dann auch sofort weitergeben. Eine gewisse Lastsituation kann ein System wie die BIG-IP selbst erkennen: Es weiß zum Beispiel, wie viele gleichzeitige Verbindungen zu einer Applikation bestehen – also wie viele Benutzer gleichzeitig an der Anwendung angemeldet sind. Aber auch Parameter wie etwa die Anzahl der Verbindungsaufbauanfragen pro Zeiteinheit liefert ein derartiges System.
Damit lässt sich dann erkennen, dass ein kritischer Bereich erreicht ist, und dass noch weitere Server mit dieser Applikation hochzufahren sind. Generell ist eine enge Verbindung von Applikations-Controller und Virtualisierungsumgebung nötig. Daher sind die üblichen Plattformen zu unterstützen: VMwares vSphere, Microsofts Hyper-V, Xen, KVM. Diese Plattformen unterstützt BIG-IP, indem es sozusagen als eine Appliance in einer eigenständigen virtuellen Maschine auf all diesen Plattformen eingesetzt werden kann. In diesem Fall ist die BIG-IP nichts anderes als eine Softwarelösung.
Automatisierter Einsatz des Cloud Bursting
Besonders interessant wird das Cloud Bursting, wenn das Umleiten von neuen Verbindungen an eine Applikation automatisch erfolgt. Dabei sollte die Entscheidung auf vordefinierten Geschäftsparametern beruhen, die im aktuellen Betrieb permanent überprüft werden, und beim Eintreffen der Kriterien ist diese Umleitung dann „von selbst“ auszuführen. Doch das Feststellen einer Überlastsituation und das Übernehmen von zusätzlichen Ressourcen für die die Anwendung (also der Start neuen VMs mit der Applikation) muss in einem engen Zeitfenster erfolgen. Das funktioniert allerdings nicht so recht, wenn die komplette Applikation mit all ihren Daten dann transferiert werden muss, sobald ein Schwellenwert erreicht ist. Denn auch der „Inhalt“ der Anwendung sollte dann bereits in der Cloud vorliegen – sprich es sollte keine komplette Live Migration stattfinden.
Damit erweist sich das Cloud Bursting vor allem dann als eine sinnvolle Architektur, die „bei Bedarf“ zum Zuge kommt, wenn bereits viele Informationen in die Cloud ausgelagert, dort aber noch nicht aktiv sind. Denn nur so kann der IT-Verantwortliche sichergehen, dass die Bereitstellung allein weniger zeitaufwändig ist, als eine komplette Live Migration mit anschließender Bereitstellung der Ressourcen. Damit wird dann eine wesentliche Forderung entstehen: Das komplette Konstrukt kann nur eine hybride Cloud-Architektur sein.
Doch dabei muss es den IT-Verantwortlichen auch klar sein: Wer heute seine Spitzenlasten etwa aufgrund von saisonalen Schwankungen zu einem Cloud-Provider auslagert, der hat sich mit mehr „Technik“ zu befassen. Denn es ist mehr zu tun, als nur eine (oder mehrere) zusätzliche virtuelle Maschinen zum Beispiel in Amazons EC2 hochzufahren. Es gilt vor allem, die Änderungen am DNS (Domain Name System) zu berücksichtigen. Zudem ist eine Richtlinie nötig, die das Umleiten der Anfragen in die Cloud realisiert. Und diese Richtlinie muss dann auch umgesetzt werden. Dabei sollte ein Unternehmen einen IT-Prozess sauber aufsetzen, der diese Aktion – mit allen nötigen Freiheitsgraden und Parametern – möglichst automatisch ablaufen lässt. Denn damit entsteht dann auch ein passendes Fundament für eine hybride Cloud-Architektur.
Doch der IT-Verantwortliche sollte auch ein dynamisches Wachstum mit einrechnen. Denn mit steigender Benutzerzahl – bei einem erfolgreichen Unternehmen wird das sicher eintreffen – wird der Schwellenwert für das Umleiten in die Cloud immer häufiger eintreten. An dieser Stelle ist dann die Entscheidung fällig: Soll immer mehr in die Cloud geschoben werden oder wird intern bei den IT-Ressourcen nachgerüstet.


